useAsyncData 훅 구현기: TanStack Query 없이 비동기 상태 관리 패턴 만들기
오답노트 서비스의 커스텀 훅들을 살펴보니 똑같은 패턴이 세 번이나 반복되고 있었습니다.
useState세 개,useCallback으로 감싼 fetch 함수,useEffect로 마운트 시 호출.
처음엔 “이 정도는 괜찮지 않나?” 싶었지만, 훅이 늘어날수록 보일러플레이트도 함께 늘어났습니다.이 글은 반복되는 비동기 상태 관리 패턴을 추상화하면서 고민한 내용을 정리한 글입니다.
문제 상황
오답노트 서비스에는 useProblems, useSettings, useTodayReviews 세 개의 커스텀 훅이 있다. 각각 문제
목록, 설정, 오늘의 복습 데이터를 관리한다.
세 훅의 코드를 나란히 놓고 보니 거의 동일한 구조가 반복되고 있었다:
// useProblems.ts
const [problems, setProblems] = useState<Problem[]>([]);
const [loading, setLoading] = useState(true);
const [error, setError] = useState<Error | null>(null);
const fetchProblems = useCallback(async () => {
try {
setLoading(true);
const data = await getAllProblems();
setProblems(data);
setError(null);
} catch (err) {
setError(
err instanceof Error ? err : new Error("Failed to fetch problems"),
);
} finally {
setLoading(false);
}
}, []);
useEffect(() => {
fetchProblems();
}, [fetchProblems]);useSettings와 useTodayReviews도 변수명과 fetch 함수만 다를 뿐 구조는 동일했다. 총 세 개의 훅에서 같은 패턴이 반복되니 약 60줄 정도의 중복 코드가 발생하고 있었다.
내가 처음 한 생각
가장 먼저 떠오른 건 TanStack Query(React Query)의 useQuery였다.
// TanStack Query를 사용한다면
const { data, isLoading, error, refetch } = useQuery({
queryKey: ["problems"],
queryFn: getAllProblems,
});TanStack Query는 비동기 상태 관리의 사실상 표준이다. 캐싱, 백그라운드 리페칭, stale-while-revalidate, 옵티미스틱 업데이트 등 강력한 기능들을 제공한다.
하지만 몇 가지 이유로 망설여졌다.
- 현재 필요한 기능이 제한적: 오답노트는 IndexedDB를 사용하는 로컬 우선 앱이다. 서버 통신이 없어서 캐싱, 리페칭, stale time 같은 기능이 크게 의미 없다.
- 번들 사이즈: TanStack Query는 약 13KB(gzipped)다. 현재 필요한 기능 대비 무겁다고 느껴졌다.
- 학습 기회: 직접 구현해보면서 비동기 상태 관리의 핵심 패턴을 이해하고 싶었다.
실제로 해 본 선택
세 훅에서 공통으로 필요한 것을 추려보니 다음과 같았다.
- data: 가져온 데이터
- loading: 로딩 상태
- error: 에러 상태
- refetch: 수동으로 다시 가져오기
- setData: 로컬에서 데이터 직접 수정 (옵티미스틱 업데이트용)
이를 바탕으로 useAsyncData 훅을 구현했다.
interface UseAsyncDataResult<T> {
data: T;
loading: boolean;
error: Error | null;
refetch: () => Promise<void>;
setData: React.Dispatch<React.SetStateAction<T>>;
}
export function useAsyncData<T>(
fetcher: () => Promise<T>,
initialData: T,
): UseAsyncDataResult<T> {
const [data, setData] = useState<T>(initialData);
const [loading, setLoading] = useState(true);
const [error, setError] = useState<Error | null>(null);
const refetch = useCallback(async () => {
try {
setLoading(true);
const result = await fetcher();
setData(result);
setError(null);
} catch (err) {
setError(err instanceof Error ? err : new Error("Failed to fetch data"));
} finally {
setLoading(false);
}
}, [fetcher]);
useEffect(() => {
refetch();
}, [refetch]);
return { data, loading, error, refetch, setData };
}이제 기존 훅들이 훨씬 간결해졌다.
// Before: 약 40줄
export function useProblems() {
const [problems, setProblems] = useState<Problem[]>([]);
const [loading, setLoading] = useState(true);
const [error, setError] = useState<Error | null>(null);
// ... fetchProblems, useEffect, addProblem, editProblem 등
}
// After: 약 25줄
export function useProblems() {
const fetcher = useCallback(() => getAllProblems(), []);
const {
data: problems,
loading,
error,
refetch,
setData,
} = useAsyncData<Problem[]>(fetcher, []);
// ... addProblem, editProblem 등 (setData 사용)
}useAsyncData vs useQuery
직접 구현한 useAsyncData와 TanStack Query의 useQuery를 비교해보면 설계 철학의 차이가 드러난다.
| 관점 | useAsyncData | useQuery (TanStack Query) |
|---|---|---|
| 캐싱 | 없음 (매번 새로 fetch) | 강력한 캐시 레이어 제공 |
| queryKey | 없음 | 캐시 무효화 및 데이터 공유의 핵심 |
| 리페칭 전략 | 수동 refetch()만 지원 | staleTime, refetchOnWindowFocus 등 자동화 |
| 데이터 공유 | 훅 인스턴스마다 데이터 독립 | 같은 queryKey면 데이터 공유 가능 |
| 옵티미스틱 업데이트 | setData로 직접 수정 | setQueryData, onMutate 활용 |
| 에러 재시도 | 없음 | retry, retryDelay 설정 가능 |
| 번들 사이즈 | ~0.3KB (gzipped) | ~13KB (gzipped) |
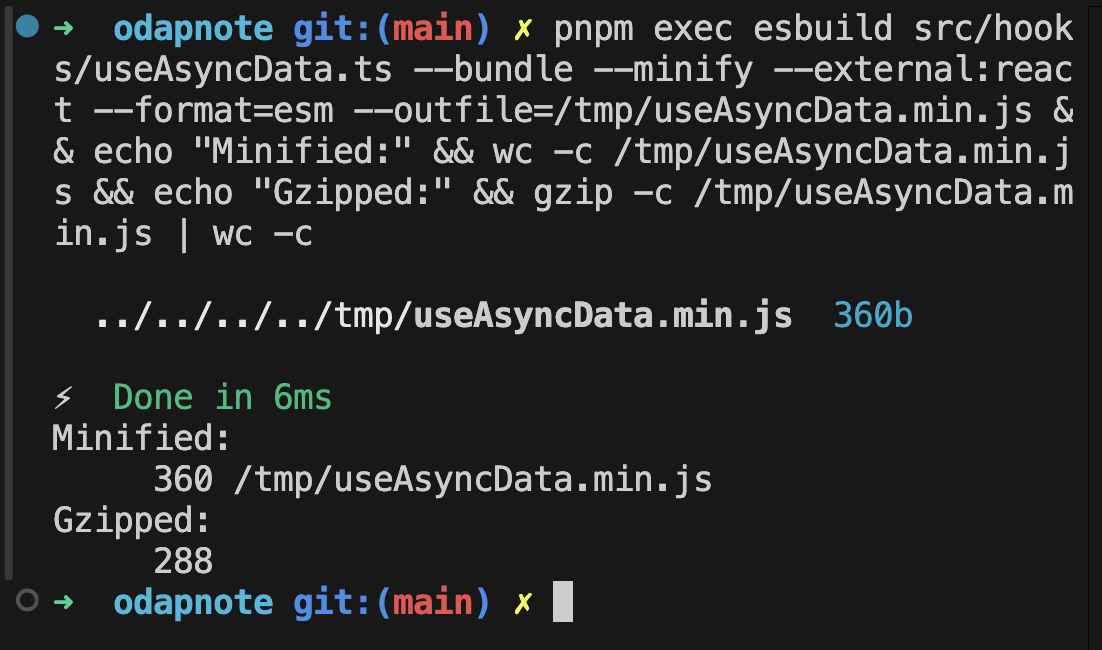
핵심적인 차이는 캐시 레이어의 유무다.
useQuery는 queryKey를 기반으로 전역 캐시를 관리한다. 같은 queryKey를 가진 컴포넌트들은 데이터를 공유하고, 하나가 refetch하면 다른 곳도 업데이트된다. 서버 상태를 여러 컴포넌트에서 구독하는 상황에서 강력하다.
// TanStack Query - 같은 queryKey면 데이터 공유
// ComponentA와 ComponentB가 같은 데이터를 바라봄
const { data } = useQuery({ queryKey: ["problems"], queryFn: getAllProblems });반면 useAsyncData는 훅을 호출하는 각 컴포넌트가 독립적인 상태를 가진다. 캐시가 없으니 queryKey도 필요없고, 구조가 단순하다. 대신 여러 컴포넌트에서 같은 데이터가 필요하면 상위에서 내려주거나, Context로 감싸야 한다.
// useAsyncData - 각 호출이 독립적
// 같은 fetcher라도 각자 따로 fetch하고 따로 상태를 가짐
const { data } = useAsyncData(getAllProblems, []);오답노트에서는 useProblems같은 훅을 최상위 페이지 컴포넌트에서 한 번만 호출하고 props로 내려주는 구조라서 데이터 공유 문제가 없었다. 서버 통신이 없어서 캐싱의 이점도 크지 않았다.
결과
세 개의 훅에서 반복되던 보일러플레이트가 제거됐고, 새로운 비동기 훅을 만들 때도 useAsyncData를 사용하면 된다.
다만 구현하면서 놓친 부분도 있었다.
1. fetcher의 deps 문제
useCallback으로 fetcher를 감싸지 않으면 매 렌더마다 새 함수가 전달되어 무한 refetch가 발생한다. 호출하는 쪽에서 useCallback을 강제해야 하는 불편함이 있다.
// 이렇게 하면 무한 루프
const { data } = useAsyncData(() => getAllProblems(), []);
// useCallback으로 감싸야 함
const fetcher = useCallback(() => getAllProblems(), []);
const { data } = useAsyncData(fetcher, []);2. useMemo 추가
반환 객체가 매번 새로 생성되면 이 훅을 사용하는 컴포넌트가 불필요하게 리렌더링될 수 있다. 각 훅에서 useMemo로 반환 객체를 감쌌다.
지금 다시 해본다면
비동기 상태 관리 도구를 선택할 때 다음 기준으로 판단할 것 같다.
TanStack Query가 적합한 경우
- 서버 API와 통신하는 앱
- 여러 컴포넌트에서 같은 서버 상태를 구독해야 할 때
- 캐싱, 백그라운드 리페칭, 페이지네이션, 인피니트 스크롤 등 고급 기능이 필요할 때
- stale-while-revalidate 패턴이 UX에 중요할 때
직접 구현이 적합한 경우
- 로컬 데이터만 다루는 앱 (IndexedDB, localStorage 등)
- 데이터 공유가 필요 없는 단순한 구조
- 번들 사이즈가 중요할 때
- 비동기 상태 관리의 동작 원리를 이해하고 싶을 때
추가로, fetcher에 useCallback을 강제하는 문제를 해결하려면 useRef로 fetcher를 저장하거나, queryKey처럼 deps 배열을 받는 방식으로 개선할 수 있다:
// 개선안: deps를 명시적으로 받기
export function useAsyncData<T>(
fetcher: () => Promise<T>,
initialData: T,
deps: React.DependencyList = [],
): UseAsyncDataResult<T> {
const refetch = useCallback(async () => {
// ...
}, deps); // fetcher 대신 deps를 의존성으로
// ...
}비고
- useQuery의 queryKey가 중요한 이유
- 캐시 키: 같은 queryKey면 데이터를 공유하고 캐시를 재사용
- 무효화 단위: queryClient.invalidateQueries({ queryKey: [‘problems’] })로 관련 쿼리 일괄 무효화
- 의존성 관리: queryKey가 바뀌면 자동으로 refetch
- 옵티미스틱 업데이트 패턴
- useAsyncData: setData로 직접 상태 수정 → 실패 시 직접 롤백
- useQuery: onMutate에서 이전 상태 저장 → 실패 시 onError에서 롤백
- 왜 로컬 앱에서 캐싱이 덜 중요한가
- 서버 통신: 네트워크 비용이 크므로 캐싱으로 요청 횟수를 줄이는 게 중요
- IndexedDB: 로컬 디스크 접근이라 빠름. 캐싱의 이점이 상대적으로 작음